Распознавание текста при помощи OCR программ теперь доступно и в Линукс
Для тестирования использовались:
- Дистрибутив:
- ALT Linux 4.0.2 Desktop
- Репозиторий:
- branch/4.0 i586
- branch/4.0 noarch
Пакеты для установки:
# apt-cache search cuneiform
- cuneiform - Программа распознавания символов (OCR) Cuneiform, Linux-версия
- cuneiform-qt - GUI frontend for Cuneiform OCR
- cuneiform-data - Поддержка различных языков и другие файлы с данными для OCR Cuneiform
Скан из LXF 118 pdf-файл, стр.32 (по нумерации журнала, по нумерации вьювера - стр.34)
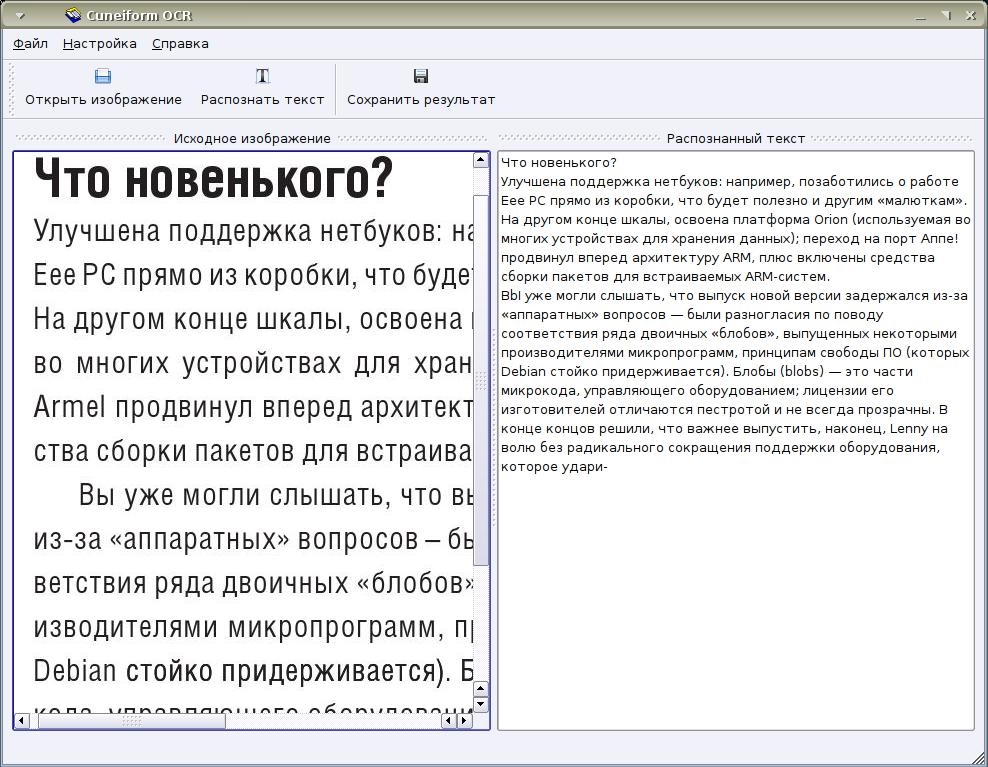
Поддержка русского и английского при распознавании
Готовый вариант распознанного текста по которому вы можете оценить качество распознавания:
Что новенького?
Улучшена поддержка нетбуков: например, позаботились о работе Еее PC прямо из коробки, что будет полезно и другим «малюткам». На другом конце шкалы, освоена платформа Orion (используемая во многих устройствах для хранения данных); переход на порт Аппе! продвинул вперед архитектуру ARM, плюс включены средства сборки пакетов для встраиваемых ARM-систем.
Вы уже могли слышать, что выпуск новой версии задержался из-за «аппаратных» вопросов — были разногласия по поводу соответствия ряда двоичных «блобов», выпущенных некоторыми производителями микропрограмм, принципам свободы ПО (которых Debian стойко придерживается). Блобы (blobs) — это части микрокода, управляющего оборудованием; лицензии его изготовителей отличаются пестротой и не всегда прозрачны. В конце концов решили, что важнее выпустить, наконец, Lenny на волю без радикального сокращения поддержки оборудования, которое удари-
Сначала снимаем скриншот масштабируя изображение побольше. Загружаем изображение в Cuneiform. В настройках выбираем язык распознавания: для русского выбор невелик - русский / русский-английский. Сохраняем распознанное.
Ссылки
- Сайт программы: launchpad.net/cuneiform-linux/
- Исходный код для скачивания: launchpad.net/cuneiform-linux/+download
- Cuneiform-Qt 0.1.1 (Графический интерфейс для системы распознавания Cuneiform: www.altlinux.org/Cuneiform-Qt
- YAGF - графическая оболочка для cuneiform: symmetrica.net/cuneiform-linux/yagf-ru.html
- Cuneiform для Linux (ветка cuneiform с расширенной функциональностью: symmetrica.net/cuneiform-linux/
Линки, советы и обсуждение:
- Новая графическая оболочка для cuneiform linuxforum.ru/index.php?showtopic=93784
- Линки на неофициальные deb-пакеты cuneiform: notesalexp.blogspot.com/search/label/cuneiform
- Линки и обсуждение Cuneiform-qt в Debian/Ubuntu: forum.ubuntu.ru/index.php?topic=54157.0;all